
Dein Vertriebsteam fragt die KI nach den Lieferzeiten für Produkt X — und bekommt eine allgemeine Antwort aus dem Wikipedia-Fundus statt die aktuelle Info aus eurem ERP-System. Standard-LLMs haben schlicht keinen Zugang zu dem Wissen, das euer Unternehmen täglich produziert. Retrieval Augmented Generation ändert das: RAG verbindet Sprachmodelle mit euren internen Datenquellen und macht aus einem generischen Chatbot einen Unternehmensassistenten, der Antworten mit Quellenangabe liefert.
Das Wichtigste in Kürze
- RAG kombiniert Informationssuche mit generativer KI und macht internes Unternehmenswissen für Sprachmodelle nutzbar — ohne teures Nachtrainieren.
- Der Prozess läuft in drei Schritten: Retrieval (Daten abrufen), Augmentation (Kontext anreichern), Generation (Antwort erstellen).
- RAG ist für die meisten Anwender die effizientere Alternative zu Fine-Tuning, weil sich Datenquellen dynamisch aktualisieren lassen.
- Hybride Retrieval-Strategien aus Vektorsuche, Keyword-Suche und Metadaten-Filtern liefern die besten Ergebnisse.
- Praxisrelevante Einsatzbereiche: Kundensupport, Wissensmanagement, Vertrieb, Compliance und Content-Erstellung.
- Für die Einführung KI-gestützter Lösungen können KMU bis zu 50 % staatliche Förderung erhalten.
Lesezeit: 8 Minuten
Inhaltsverzeichnis
- Was ist RAG und warum reichen Standard-KI-Modelle nicht aus?
- Wie funktioniert RAG? Die drei Schritte einfach erklärt
- RAG vs. Fine-Tuning: Warum RAG für die meisten Unternehmen die bessere Wahl ist
- Praktische Anwendungsfälle: So setzen Unternehmen RAG im Alltag ein
- Technische Bausteine: Embeddings, Vektordatenbanken und Retrieval-Strategien
- Best Practices für die erfolgreiche RAG-Einführung
- Nächster Schritt: RAG-Potenzial für euer Unternehmen bewerten lassen
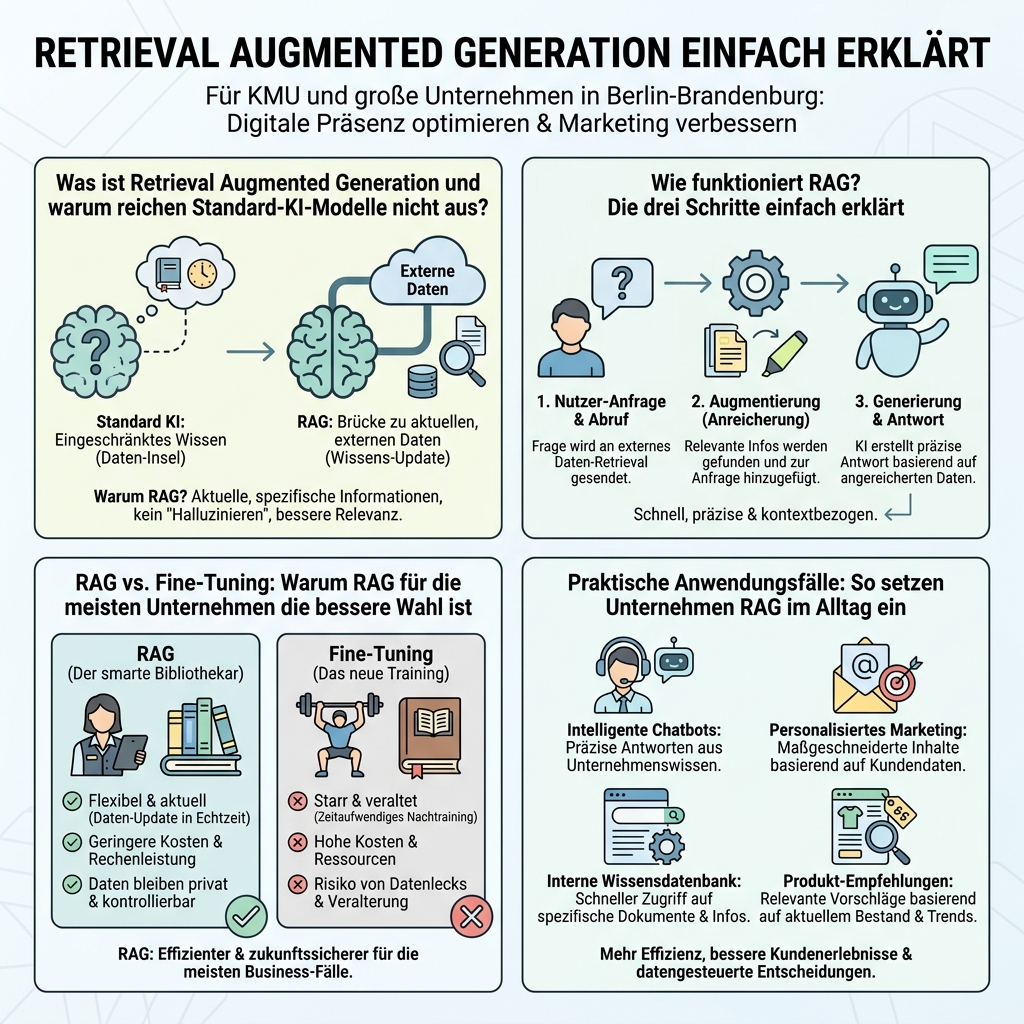
Was ist RAG und warum reichen Standard-KI-Modelle nicht aus?
Wer KI-Anwendungen im Unternehmen einsetzt, stößt schnell auf eine ernüchternde Grenze: Das Modell kennt die Welt — aber nicht euer Unternehmen.
Retrieval Augmented Generation (RAG) ist ein Architekturansatz, der generative Sprachmodelle mit einer Informationsabruf-Komponente verbindet. Statt sich ausschließlich auf vortrainiertes Wissen zu verlassen, ruft ein RAG-System bei jeder Anfrage gezielt Informationen aus externen Datenquellen ab — etwa aus eurem Firmen-Wiki, der Produktdatenbank oder dem Kundenservice-Handbuch. Auf dieser Grundlage generiert das LLM eine Antwort, die auf echten, aktuellen Unternehmensdaten basiert.
Warum das nötig ist? Standard-LLMs kennen nur ihre Trainingsdaten bis zu einem bestimmten Stichtag. Sie haben keinen Zugriff auf interne Dokumente, Prozessbeschreibungen oder aktuelle Produktinformationen. Bei firmenspezifischen Fragen liefern sie deshalb entweder vage Allgemeinplätze oder — schlimmer — frei erfundene Antworten, sogenannte Halluzinationen.
Entscheidender als der Trainingskorpus eines LLMs ist der Kontext, der mit der Eingabe übergeben wird. Da Sprachmodelle auf Basis dieses Kontexts das nächste Token vorhersagen, führt ein informativ gestalteter Kontext zu deutlich präziseren Ergebnissen als das bloße Vertrauen auf vortrainiertes Wissen (Informatik Aktuell). Der Hebel für euer Unternehmen: Wer den richtigen Kontext liefert, bekommt brauchbare Antworten — wer nicht, bekommt Rauschen.
Berliner KMU sitzen häufig auf umfangreichen Wissensbeständen in Confluence, SharePoint oder Google Drive. Ohne RAG bleibt dieses Wissen für KI-Anwendungen unsichtbar. RAG macht es zugänglich — ohne dass das Modell neu trainiert werden muss. Das senkt die Einstiegshürde erheblich.
Wie funktioniert RAG? Die drei Schritte einfach erklärt
Das Grundprinzip von RAG lässt sich auf drei klar abgegrenzte Schritte herunterbrechen. Die Komplexität steckt im Detail — das Konzept ist überraschend eingängig.
Schritt 1 — Retrieval (Abrufen): Die Nutzeranfrage wird entgegengenommen und dazu genutzt, aus einer externen Datenquelle die relevantesten Dokumente oder Textabschnitte zu finden. In der Praxis geschieht das über eine Vektordatenbank, in der eure Unternehmensdokumente als mathematische Repräsentationen (Embeddings) gespeichert sind. Die Anfrage wird ebenfalls in einen Vektor umgewandelt und mit den gespeicherten Vektoren abgeglichen — ähnlich einer Bedeutungssuche statt einer reinen Stichwortsuche.
Schritt 2 — Augmentation (Anreichern): Die gefundenen Textpassagen werden dem LLM als erweiterter Kontext übergeben. Das passiert typischerweise als zusätzliche System-Message mit dem klaren Hinweis: „Beantworte die Frage auf Basis dieser Informationen.“ So wird der Kontext des Sprachmodells gezielt um relevantes Unternehmenswissen erweitert.
Schritt 3 — Generation (Erzeugen): Das LLM erstellt auf Grundlage des angereicherten Kontexts eine Antwort. Der Unterschied zu einer normalen Textgenerierung: Das Modell stützt sich auf die bereitgestellten Fakten statt auf statistische Wahrscheinlichkeiten aus dem Trainingskorpus. Das Ergebnis ist eine quellengestützte, nachvollziehbare Antwort.
Der entscheidende Faktor für die Antwortqualität ist der erste Schritt. Werden die falschen Dokumente gefunden, produziert auch das beste Sprachmodell keine brauchbare Antwort. Deshalb fließt erfahrungsgemäß der größte Optimierungsaufwand in die Retrieval-Komponente — von der Chunking-Strategie über die Wahl des Embedding-Modells bis zum Reranking.
Ein greifbares Beispiel: Ein neuer Mitarbeitender fragt den internen KI-Assistenten nach dem Onboarding-Prozess. Das RAG-System durchsucht das Firmen-Wiki, findet die relevanten Artikel zum Onboarding, übergibt sie als Kontext an das LLM — und generiert eine präzise Antwort mit Verweis auf die Originalquelle. Ohne RAG hätte das Modell bestenfalls eine allgemeine Antwort geliefert, die mit eurem tatsächlichen Prozess nichts zu tun hat.

RAG vs. Fine-Tuning: Warum RAG für die meisten Unternehmen die bessere Wahl ist
Wenn es darum geht, ein Sprachmodell an Unternehmenswissen anzupassen, stehen zwei Wege zur Verfügung: Fine-Tuning und RAG. Beide haben Berechtigung — aber für KMU ist die Abwägung in den meisten Fällen eindeutig.
Fine-Tuning bedeutet, ein bestehendes Sprachmodell mit eigenen Daten nachzutrainieren. Das Modell lernt domänenspezifisches Vokabular, Muster und Zusammenhänge. Der Haken: Der Wissensstand wird dabei eingefroren. Wenn sich Dokumente ändern oder neue hinzukommen, muss das Modell aufwändig nachtrainiert werden.
Fine-getunte Modelle generieren zwar schneller Antworten, weil kein Retrieval-Schritt vorgeschaltet ist. Doch die Aktualisierung des Wissensstands durch erneutes Training erfordert große Datenmengen, eine funktionierende Data-Engineering-Pipeline, Fachwissen und teure Hardware oder Cloud-Instanzen. Für die meisten Anwender ist RAG deshalb die effizientere Alternative (Informatik Aktuell).
RAG vs. Fine-Tuning im Vergleich
| Kriterium | RAG | Fine-Tuning |
|---|---|---|
| Aktualität der Daten | Dynamisch — greift auf aktuelle Quellen zu | Eingefroren — erfordert Nachtraining |
| Kosten | Moderat — keine Trainingsinfrastruktur nötig | Hoch — GPU-Ressourcen, Daten-Pipeline |
| Antwortgeschwindigkeit | Etwas langsamer (Retrieval-Schritt) | Schneller (kein Abruf) |
| Quellenangaben | Ja — Antworten mit Verweis auf Originaldokument | Nein — Wissen ist im Modell verschmolzen |
| Flexibilität bei neuen Daten | Hoch — neue Dokumente sofort nutzbar | Gering — Nachtraining erforderlich |
| Einstiegshürde für KMU | Niedrig | Hoch |
Gerade für mittelständische Unternehmen in Berlin und Brandenburg, die agil arbeiten und deren Produktinfos, Richtlinien oder Preislisten sich regelmäßig ändern, bietet RAG einen entscheidenden Vorteil: Neue Dokumente werden indexiert und sind sofort für die KI verfügbar — ohne Nachtraining, ohne Wartezeit. Wer verstehen will, wie sich KMU generell für KI-gestützte Suche positionieren, findet in unserem Beitrag zur Generative Engine Optimization für KMU weiterführende Strategien.
Fine-Tuning hat seine Berechtigung — etwa bei hochspezialisierten Fachsprachen oder wenn extrem niedrige Latenzzeiten gefordert sind. Für die Mehrheit der KMU-Anwendungsfälle ist RAG aber der pragmatischere und wirtschaftlich sinnvollere Weg.
Praktische Anwendungsfälle: So setzen Unternehmen RAG im Alltag ein
RAG entfaltet seinen Wert erst dort, wo konkretes Unternehmenswissen gefragt ist. Die folgenden Use Cases zeigen, wo sich der Einsatz besonders rechnet.
- Kundensupport und Helpdesk: Ein Chatbot mit Zugriff auf die Produktdokumentation beantwortet spezifische Fehlercodes sofort — inklusive Seitenverweis. Erste Antworten kommen in Sekunden statt Minuten, die Eskalationsrate zum Second-Level-Support sinkt messbar.
- Internes Wissensmanagement: Mitarbeitende stellen Fragen an einen KI-Assistenten, der auf das Firmen-Wiki, Prozesshandbücher oder HR-Richtlinien zugreift. Statt minutenlanger Stichwortsuche liefert das System eine präzise Antwort mit Quellenangabe.
- Vertrieb und Produktinformation: Vertriebsteams erhalten auf Anfrage sofort Produktspezifikationen, Preislisten und Feature-Vergleiche aus indexierten Datenblättern. Die Angebotserstellung beschleunigt sich erheblich.
- Compliance und Recht: Eine dialogbasierte Suche durch regulatorische Texte liefert automatische Zitationen der maßgeblichen Paragraphen. Compliance-Teams klären rechtliche Fragen, ohne Stunden in Gesetzestexten zu verbringen.
- Content-Erstellung und Recherche: Der automatische Abruf aktueller Statistiken und Studien mit korrekten Quellenangaben beschleunigt die Content-Produktion. Autor:innen arbeiten faktenbasiert, ohne manuelle Recherche.
Ein Berliner Dienstleistungsunternehmen mit mehreren Standorten in Brandenburg kann RAG nutzen, um standortübergreifendes Wissen aus verschiedenen Systemen — CRM, Wiki, Ticket-System — zentral und sofort abrufbar zu machen. Die Mitarbeitenden fragen, das System antwortet auf Basis der tatsächlichen Unternehmensdaten. Das ist der Unterschied zwischen „KI ist ganz nett“ und „KI spart uns Stunden pro Woche“.
Technische Bausteine: Embeddings, Vektordatenbanken und Retrieval-Strategien
Wer RAG erfolgreich einsetzen will, sollte die zentralen technischen Komponenten verstehen. Keine Sorge — das Prinzip ist logisch, auch ohne Data-Science-Hintergrund.
Embeddings sind mathematische Vektoren, die den Bedeutungsgehalt von Texten abbilden. Dokumente werden zunächst in kleinere Abschnitte (sogenannte Chunks) aufgeteilt — typischerweise zwischen 500 und 1.000 Wörtern. Jeder Chunk wird dann durch ein Embedding-Modell in einen Vektor umgewandelt. Wörter und Passagen mit ähnlicher Bedeutung erhalten dabei ähnliche Vektoren, auch wenn sie unterschiedliche Begriffe verwenden. „Lieferzeit“ und „Versanddauer“ landen also nah beieinander im Vektorraum.
Diese Vektoren werden in einer Vektordatenbank gespeichert. Bei jeder Nutzeranfrage wird die Frage ebenfalls in einen Vektor umgewandelt und per Ähnlichkeitssuche (z. B. Cosine Similarity) mit den gespeicherten Vektoren abgeglichen. Die relevantesten Chunks werden als Kontext an das LLM übergeben.
Reine Vektorsuche allein reicht in der Praxis aber nicht aus. Sie findet semantisch ähnliche Inhalte, kann aber exakte Begriffe, Produktnummern oder Datumsangaben übersehen. Deshalb setzen gut konfigurierte RAG-Systeme auf hybride Retrieval-Strategien:
- Vektorsuche für semantische Ähnlichkeit — findet thematisch passende Passagen auch bei anderer Wortwahl
- Keyword-Suche für exakte Begriffe — unverzichtbar bei Artikelnummern, Eigennamen oder Fachbegriffen
- Metadaten-Filter für kontextuelle Einschränkungen — etwa nach Abteilung, Dokumenttyp oder Gültigkeitsdatum
Ein nachgeschalteter Reranking-Schritt sortiert die gefundenen Ergebnisse nach finaler Relevanz. Erst dann gehen die besten Treffer an das Sprachmodell. Dieses Zusammenspiel entscheidet darüber, ob die Antwort trifft oder am Thema vorbeigeht.
Bei der Optimierung einer RAG-Pipeline spielen drei Metriken die zentrale Rolle: Genauigkeit (werden die richtigen Dokumente gefunden?), Geschwindigkeit (wie lange dauert der Retrieval-Schritt?) und Speicherbedarf (wie viel Infrastruktur wird benötigt?). Letzterer wirkt sich direkt auf die laufenden Kosten aus — ein Aspekt, der gerade für KMU mit begrenztem Budget relevant ist.
Best Practices für die erfolgreiche RAG-Einführung
RAG entfaltet sein volles Potenzial nur dann, wenn bestimmte Grundsätze beachtet werden. Die folgenden Empfehlungen basieren auf bewährten Mustern aus erfolgreichen Implementierungen.
Datenqualität als Fundament: Die Qualität der RAG-Antworten hängt direkt von der Qualität und Struktur eurer Quelldokumente ab. Veraltete, widersprüchliche oder schlecht formatierte Inhalte führen zu schlechten Antworten — unabhängig davon, wie gut das Retrieval konfiguriert ist. Bevor ihr RAG einführt, solltet ihr eure Wissensbasis aufräumen. Erfahrungsgemäß ist das der Schritt, der am meisten unterschätzt wird.
Prompt-Design mit klarer Struktur: Trennt im Prompt Kontext, Frage und Anweisungen sauber voneinander. Setzt Guardrails, damit das LLM nur auf Basis des bereitgestellten Kontexts antwortet und bei fehlender Information ehrlich sagt: „Dazu habe ich keine Informationen.“ Das reduziert Halluzinationen drastisch.
- Evaluation mit Referenzfragen: Erstellt ein Set von Testfragen mit bekannten Antworten. Messt Precision und Recall der Retrieval-Komponente sowie die Nutzerzufriedenheit mit den generierten Antworten.
- A/B-Tests für Konfiguration: Variiert Chunk-Größen, Embedding-Modelle und Retrieval-Strategien systematisch. Kleine Änderungen an der Chunk-Größe können die Antwortqualität signifikant beeinflussen.
- Token-Budgets und Caching: Setzt Obergrenzen für die Token-Nutzung pro Anfrage und cachet häufig abgerufene Chunks. Das spart Kosten und verbessert die Antwortzeit.
- Zugriffsrechte und Datenschutz: Filtert Antworten auf Basis der Benutzerberechtigungen. Nicht jeder Mitarbeitende soll auf Gehaltsdaten oder vertrauliche Verträge zugreifen können — auch nicht über den KI-Assistenten.
Erfahrungsgemäß gelingt die Einführung am besten mit einem klar abgegrenzten Pilotprojekt — etwa einem FAQ-Bot für den Kundensupport oder einem internen Wissensassistenten für eine einzelne Abteilung. Daraus lassen sich Erkenntnisse gewinnen, die ihr auf weitere Anwendungsfälle übertragt. Eine solide digitale Basis spielt dabei eine wichtige Rolle: Wer seine Website bereits responsiv und performant aufgestellt hat, schafft auch bessere Voraussetzungen für die Integration KI-gestützter Touchpoints.
Nächster Schritt: RAG-Potenzial für euer Unternehmen bewerten lassen
RAG ist keine Zukunftsmusik — es ist eine heute verfügbare Technologie, die sich auch für kleine und mittlere Unternehmen wirtschaftlich rechnet.
Der Einstieg beginnt nicht mit Technik, sondern mit einer Frage: Wo verbringen eure Mitarbeitenden die meiste Zeit mit Suchen? Ob Kundensupport, Vertrieb oder Compliance — dort, wo Wissen verstreut liegt und täglich gebraucht wird, entfaltet RAG den größten Hebel.
Identifiziert einen konkreten Anwendungsfall mit messbarem Nutzen: kürzere Antwortzeiten, weniger Eskalationen, schnellere Angebotserstellung. Ein solcher Pilotfall liefert harte Zahlen, mit denen ihr den Ausbau intern argumentieren könnt.
Für digitale Maßnahmen wie die Einführung KI-gestützter Lösungen können KMU bis zu 50 % staatliche Förderung erhalten. Dieses Budget macht den Einstieg auch für Unternehmen realistisch, die keine sechsstelligen IT-Budgets haben. Die gewusst-wo Berlin Brandenburg GmbH unterstützt Unternehmen in der Region bei der strategischen Planung und Umsetzung — von der Bedarfsanalyse über die Architekturempfehlung bis zur Omnichannel-Integration.
Ob RAG der richtige nächste Schritt für euch ist, lässt sich in einem kostenlosen Erstgespräch klären. Gemeinsam bewerten wir eure Datenquellen, identifizieren den vielversprechendsten Use Case und skizzieren eine maßgeschneiderte Strategie — abgestimmt auf eure Unternehmensziele und euer Budget.
RAG-Einführung: Umsetzungs-Checkliste für KMU
Phase 1: Bestandsaufnahme
- [ ] Identifizieren, wo Mitarbeitende die meiste Zeit mit Informationssuche verbringen
- [ ] Datenquellen inventarisieren (Wiki, CRM, SharePoint, Dateiablagen, Ticket-Systeme)
- [ ] Einen konkreten Pilotfall mit messbarem Nutzen auswählen
- [ ] Fördermöglichkeiten prüfen (bis zu 50 % staatliche Förderung für digitale Maßnahmen)
Phase 2: Datenvorbereitung
- [ ] Quelldokumente auf Aktualität und Widersprüche prüfen
- [ ] Veraltete oder redundante Inhalte bereinigen
- [ ] Chunking-Strategie festlegen (Abschnittsgröße, Überlappung)
- [ ] Metadaten definieren (Dokumenttyp, Abteilung, Gültigkeitsdatum)
Phase 3: Technische Umsetzung
- [ ] Embedding-Modell und Vektordatenbank auswählen
- [ ] Hybride Retrieval-Strategie konfigurieren (Vektor + Keyword + Metadaten-Filter)
- [ ] Reranking-Schritt implementieren
- [ ] Prompt-Design mit Guardrails aufsetzen (nur auf Kontext antworten)
Phase 4: Evaluation und Rollout
- [ ] Referenzfragen-Set mit bekannten Antworten erstellen
- [ ] Precision, Recall und Nutzerzufriedenheit messen
- [ ] A/B-Tests für Chunk-Größen und Embedding-Modelle durchführen
- [ ] Token-Budgets und Caching-Strategie definieren
- [ ] Zugriffsrechte und Datenschutzregeln implementieren
- [ ] Pilotprojekt auswerten und auf weitere Use Cases skalieren
Tipp: Speichern Sie diese Checkliste als Screenshot!
Fazit: RAG als praxisnahe Loesung fuer KMU, die ihre internen Daten und ihr Unternehmenswissen endlich fuer KI-Anwendungen erschliessen wollen, ohne teure Modelle neu trainieren zu muessen.
RAG schließt die Lücke zwischen dem, was generative KI kann, und dem, was euer Unternehmen tatsächlich braucht: präzise Antworten auf Basis eurer eigenen Daten. Die Technologie ist ausgereift, die Einstiegshürde für KMU niedrig — und mit der richtigen Strategie rechnet sich ein Pilotprojekt schnell.
Ihre nächsten Schritte:
- Identifiziert den Bereich mit dem höchsten Suchaufwand in eurem Unternehmen
- Prüft eure vorhandenen Datenquellen auf Qualität und Struktur
- Vereinbart ein kostenloses Erstgespräch mit der gewusst-wo Berlin Brandenburg GmbH unter +49 (0) 30 55629791 oder info@gewusst-wo.berlin
Lasst uns gemeinsam prüfen, wo RAG in eurem Unternehmen den größten Hebel hat — kostenlos und unverbindlich.
Häufig gestellte Fragen
Wir verhelfen Ihrem Projekt zum Erfolg!
Sie sind nur einen Klick entfernt von einer Präsenz, die nicht nur gut aussieht, sondern auch funktioniert. Nutzen Sie unser Expertenwissen in UX- und Web-Design, Marketing, Automatisierungen, Künstliche Intelligenz um Ihre Online-Präsenz zu optimieren.



